
AWS Glue: Processando MILHARES de Arquivos no S3 com Paralelismo e Escalabilidade
Quando falamos em processamento de dados em larga escala dentro da AWS, um dos serviços mais conhecidos é o AWS Glue. Muitas pessoas enxergam o Glue apenas como uma ferramenta de ETL “visual” ou como um serviço que executa um único script batch para transformar dados. Porém, o que realmente chama atenção é a capacidade de paralelização e distribuição do processamento, permitindo tratar milhares de arquivos de forma extremamente rápida e escalável.
O que é o AWS Glue?
O AWS Glue é um serviço serverless de integração de dados criado para facilitar ETL (Extract, Transform and Load), catalogação e processamento distribuído de dados.
Por trás dos panos, o Glue utiliza Apache Spark, o que significa que o processamento não acontece de forma linear em apenas uma thread ou processo. O Glue consegue dividir cargas de trabalho em múltiplas partições e distribuí-las entre diversos workers executando em paralelo.
Na prática, isso significa que um único job consegue processar milhares de arquivos simultaneamente sem precisar criar manualmente múltiplos scripts ou servidores.
A Limitação que Muitos Encontram
Um ponto que costuma gerar dúvidas é que normalmente um Job do Glue executa um único script Python ou Scala.
Isso leva algumas pessoas a acreditarem que:
- o processamento é sequencial;
- o Glue lê arquivo por arquivo;
- ou que seria necessário criar milhares de execuções separadas.
Mas não é assim que o Glue funciona.
Mesmo utilizando apenas um script, o processamento é distribuído automaticamente pelo Spark, permitindo paralelismo massivo dependendo da forma como os dados são lidos e organizados.
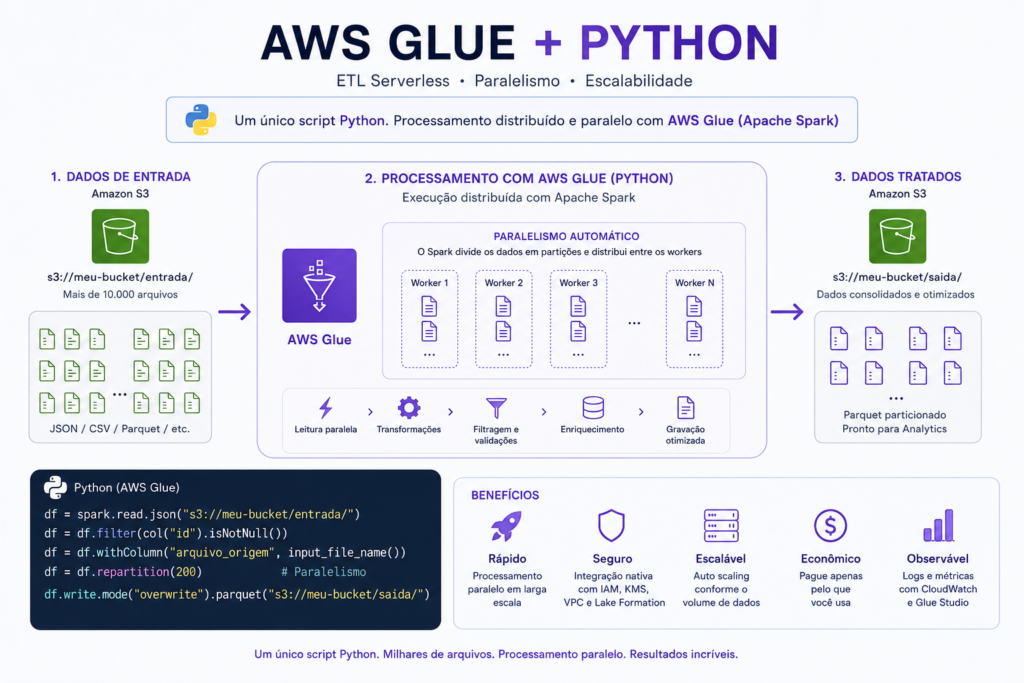
Cenário Real: Mais de 10.000 Arquivos no Amazon S3
Imagine o seguinte cenário:
- Uma pasta no Amazon S3 recebe continuamente arquivos JSON.
- Existem mais de 10.000 arquivos pequenos.
- Cada arquivo precisa ser validado, transformado e consolidado.
- O processamento precisa ser rápido, resiliente e escalável.
Muitas aplicações tradicionais sofreriam com:
- consumo excessivo de memória;
- gargalos de I/O;
- loops extremamente lentos;
- necessidade de múltiplas threads manuais;
- gerenciamento complexo de infraestrutura.
Com o AWS Glue, o comportamento é diferente.
Como o Paralelismo Funciona
Ao ler uma pasta inteira do S3, o Spark consegue distribuir automaticamente os arquivos entre os workers disponíveis.
Exemplo simplificado:
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
df = spark.read.json("s3://meu-bucket/eventos/")Mesmo com apenas uma linha de leitura, o Spark pode:
- dividir os arquivos em partições;
- distribuir essas partições entre executores;
- processar múltiplos arquivos simultaneamente;
- escalar horizontalmente conforme a quantidade de workers.
Na prática, milhares de arquivos podem ser processados em paralelo.
O Grande Benefício: Escalabilidade Transparente
O mais interessante é que o desenvolvedor não precisa gerenciar:
- threads;
- filas;
- sincronização;
- balanceamento de carga;
- clusters manualmente.
O Glue abstrai toda essa complexidade.
Você configura:
- quantidade de workers;
- tipo do worker;
- memória;
- timeout;
- versão do Glue.
E o serviço escala automaticamente o processamento distribuído.
Exemplo Prático de Processamento
Imagine uma pasta contendo:
s3://logs-aplicacao/2026/05/17/Com:
- 10.000+ arquivos JSON;
- eventos de aplicações;
- logs de APIs;
- mensagens Kafka exportadas;
- dados de auditoria.
O Glue pode:
- Ler todos os arquivos em paralelo;
- Aplicar transformações distribuídas;
- Filtrar registros inválidos;
- Consolidar em parquet;
- Gravar em outro bucket otimizado para analytics.
Exemplo:
df = spark.read.json("s3://logs-aplicacao/2026/05/17/")
df_filtrado = df.filter(df.status == "SUCCESS")
df_filtrado.write.mode("overwrite").parquet(
"s3://data-lake-processado/logs/"
)Esse processamento pode ocorrer utilizando dezenas de executores simultâneos.
Pequenos Arquivos: O Problema Clássico
Existe inclusive um problema conhecido no ecossistema Spark chamado:
“Small Files Problem”
Quando existem milhares de arquivos pequenos, sistemas tradicionais costumam sofrer bastante.
Mesmo assim, o Glue consegue reduzir significativamente esse impacto utilizando:
- paralelização;
- particionamento;
- execução distribuída;
- leitura otimizada no S3.
Além disso, após o processamento, é possível consolidar milhares de arquivos pequenos em arquivos parquet maiores e mais eficientes.
Isso melhora:
- performance de consultas;
- leitura no Amazon Athena;
- consumo no Amazon Redshift;
- pipelines downstream.
Segurança e Governança
Outro ponto forte do AWS Glue é a integração nativa com o ecossistema AWS:
- IAM para controle de permissões;
- KMS para criptografia;
- VPC para isolamento de rede;
- CloudWatch para observabilidade;
- Glue Data Catalog para metadados;
- Lake Formation para governança.
Tudo isso sem necessidade de administrar servidores manualmente.
Quando o AWS Glue Brilha
O Glue se destaca principalmente quando:
- há grande volume de arquivos;
- o processamento precisa ser distribuído;
- existe integração forte com S3/Data Lake;
- o time quer evitar gerenciar clusters Spark manualmente;
- o workload é batch e orientado a dados.
Segue abaixo o exemplo completo do código
import sys
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
from pyspark.sql.functions import col, input_file_name, current_timestamp
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
"INPUT_PATH",
"OUTPUT_PATH",
"NUM_PARTITIONS"
]
)
sc = SparkContext()
glue_context = GlueContext(sc)
spark = glue_context.spark_session
job = Job(glue_context)
job.init(args["JOB_NAME"], args)
input_path = args["INPUT_PATH"]
output_path = args["OUTPUT_PATH"]
num_partitions = int(args["NUM_PARTITIONS"])
spark.conf.set("spark.sql.files.ignoreCorruptFiles", "true")
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
df = (
spark.read
.option("multiLine", "false")
.json(input_path)
)
df = df.withColumn("arquivo_origem", input_file_name())
df = df.withColumn("data_processamento", current_timestamp())
df_processado = (
df
.filter(col("id").isNotNull())
.repartition(num_partitions)
)
df_processado.write \
.mode("overwrite") \
.option("compression", "snappy") \
.parquet(output_path)
job.commit()Considerações Finais
Apesar de muita gente enxergar o AWS Glue apenas como “um script ETL rodando na AWS”, a realidade é que ele entrega um poder enorme de processamento distribuído utilizando Spark de forma serverless.
A possibilidade de processar mais de 10.000 arquivos no S3 de maneira paralela, rápida e escalável transforma completamente a forma como pipelines de dados podem ser construídos.
Sem precisar gerenciar infraestrutura, filas ou concorrência manualmente, o Glue permite focar no que realmente importa: os dados e as regras de negócio.
Para workloads orientados a Data Lake, ingestão massiva e transformação batch, ele continua sendo uma das soluções mais poderosas dentro do ecossistema AWS.




